The numbers are in, and they're uncomfortable. Claude Opus 4.7 scores 87.6% on SWE-bench Verified. Gemini 3.1 Pro tops 50% on broader coding benchmarks. Impressive, right? Now look at SWE-bench Pro: the same models hover around 23%. That's not a rounding error. That's a chasm.
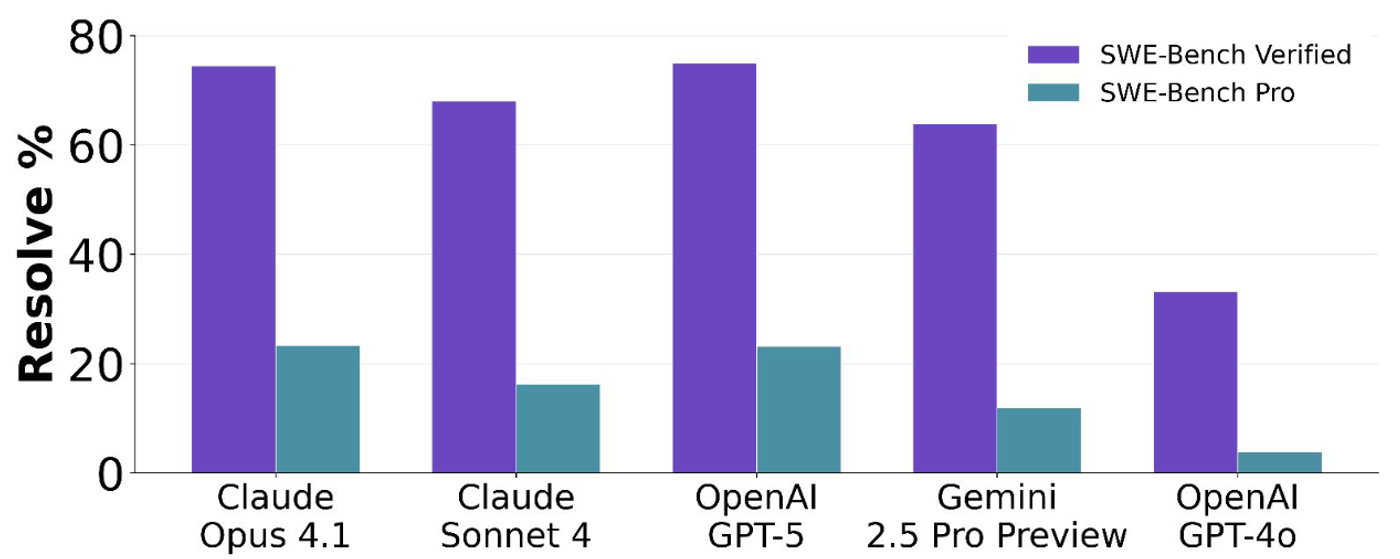
SWE-bench Verified vs Pro: top models score 70-93% on Verified but only ~23% on Pro
The gap isn't subtle. Models that look production-ready on Verified suddenly look like interns on their first day when you raise the bar. And that's exactly the point.
Why This Matters Now
Three forces are converging. First, Stanford's 2026 AI Index dropped this week, confirming what practitioners already feel: model accuracy on standardized benchmarks has plateaued in the high 30s for general tasks, even as coding-specific benchmarks show steeper gains. The best models now crack 50% on multi-step reasoning benchmarks, but that still means they fail half the time on tasks requiring chained decisions.
Second, the "vibe coding" conversation has matured. A year after Andrej Karpathy coined the term, the industry has moved past the initial hype-panic cycle. The Pragmatic Engineer's latest survey shows engineers settling into a pragmatic middle ground: AI handles the grunt work—nagging bugs, boilerplate, P1 optimization—while humans architect, review, and own the blast radius. DHH reported that one of his most "agent-accelerated" engineers at 37signals optimized the fastest 1% of web requests, a task that previously wasn't worth the time investment. That's the real productivity story: not replacing engineers, but making marginal work economically viable.
Third, Google's Agent Bake-Off produced five concrete tips for building production-grade agents, and they all point in the same direction: rigorous evaluation beats prompt engineering. Multi-agent architectures, multimodal integration, and structured feedback loops aren't optional accessories—they're the difference between a demo and a deployment.
The Real Benchmark Is Your Production Environment
Here's the uncomfortable truth that SWE-bench Pro makes visible: your agent's performance on curated benchmarks tells you almost nothing about how it will perform in your codebase. Your monorepo with 2,000 packages, your 15-year-old migration scripts, your deployment pipeline that requires three manual approvals—none of that exists in the benchmark.
The engineers getting real value from coding agents aren't the ones chasing benchmark scores. They're the ones who've built evaluation loops around their own repos. They run agents against their own failing tests, their own code review standards, their own definition of done. The benchmark that matters is the one you build yourself.
What This Means for Agent Builders
If you're building on top of coding agents, this week's data points to a clear strategy:
Invest in evaluation infrastructure before you invest in model selection. The model landscape shifts monthly; your eval harness compounds.
Design for the 23%, not the 87%. If your architecture assumes your agent will succeed most of the time, it will fail catastrophically when it doesn't. Build retry logic, human-in-the-loop checkpoints, and rollback paths as first-class concerns.
Separate vibe from value. The agent that writes a beautiful React component in 30 seconds is impressive. The agent that identifies a race condition in your payment service at 3 AM and proposes a fix that passes your existing test suite—that's valuable.
The benchmarks are finally catching up to reality. SWE-bench Pro isn't a gotcha. It's a diagnostic. And the diagnosis is clear: we've built agents that excel at homework problems. Now we need to build systems that excel at the real ones.
The gap between 87% and 23% isn't a bug in the benchmark. It's a feature of the truth.